Anonymising
Mapsafe plugin offers halo masking and hexabining to anonymise geospatial datasets.
The Annonymise tab permits these tasks after the geospatial file is loaded into QGIS from the file system:
Geographic masking
Geographic masks are a set of techniques that alter the location of points in a map to protect privacy without overly affecting any spatial patterns. In other words, geographic masks allow researchers to publish useful maps of approximate locations, without exposing sensitive data or violating anyone's privacy. Of course, this is a trade-off: with more masking comes more privacy, but this privacy comes as the cost of information loss. If we apply too much masking to our data, the end result may not resemble the original data whatsoever. While the balance between privacy and information loss can be tricky, its best to air on the side of privacy.
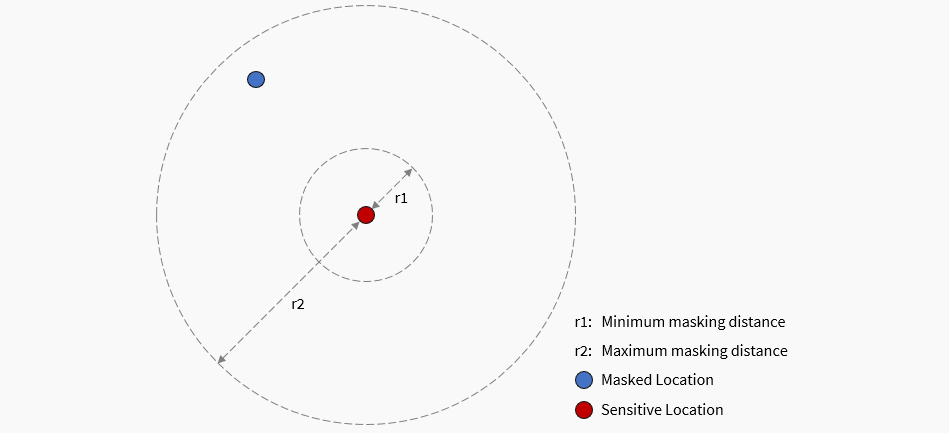
Mapsafe uses the Maskmy.XYZ tool for masking. The tool performs donut masking, which is a funny term for a simple concept: moving each point randomly between a minimum and maximum distance.
A more comprehensive explanation of the masking feature can be found on this document.
Spruill's Measure
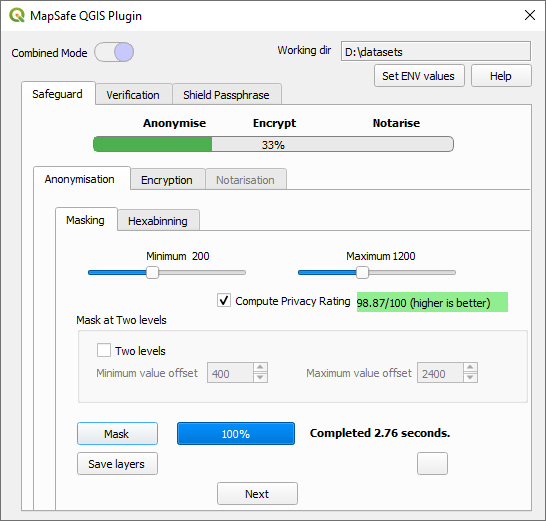
Our privacy rating is an approximate measure of the likelihood that your data could be re-identified by an external party. Ensuring privacy requires masked locations to be further from the original points, whereas maintaining utility entails the opposite. To this end, we assist users in determining whether their chosen minimum and maximum boundaries are adequate in preventing the locations from being vulnerable to re-identification. The Spruill's measure yields a privacy rating based on the percentage of masked points that are closer to any of the original points (refer to this paper). This measure is adapted from Spruill's measure, but inverted to represent a privacy rating instead of a disclosure risk rating.
According to Armstrong et al. (1999), Spruill's measure is defined as follows: "For each record in the masked dataset (M), calculate the distance between its geographic coordinates and those of each record in the original dataset (X). Spruill's measure, denoted as S, is the proportion of records in M that are closer to their corresponding 'parent' records than to any other record in X. A masking method where a large number of records are closest to their parent records is considered to have a high disclosure risk."
To ensure privacy while masking, when choosing the minimum and maximum boundary to displace the coordinates, the user would normally specify a large displacement area (distance between minimum and maximum). However, the displacement area depends on two factors:
- since each dataset has a different coverage, the minimum and maximum values need to be chosen accodingly
- how much to anonymise would vary depending on the user's requirement.
Therefore, for each dataset, a user would normally make multiple masking attempts using the Privacy Rating, to finally determine the best minimum and maximum boundaries based on the user's requirement. In this regard, Ema can keep adjusting the boundaries until a reasonable rating is achieved.
This measure was adopted in the (https://www.MaskMy.xyz web application) to assist users in donut masking.
For the same purpose, (https://www.MapSafe.xyz web application) also uses this feature. Once masked, the layers can be saved using the Save button.
Halo masking
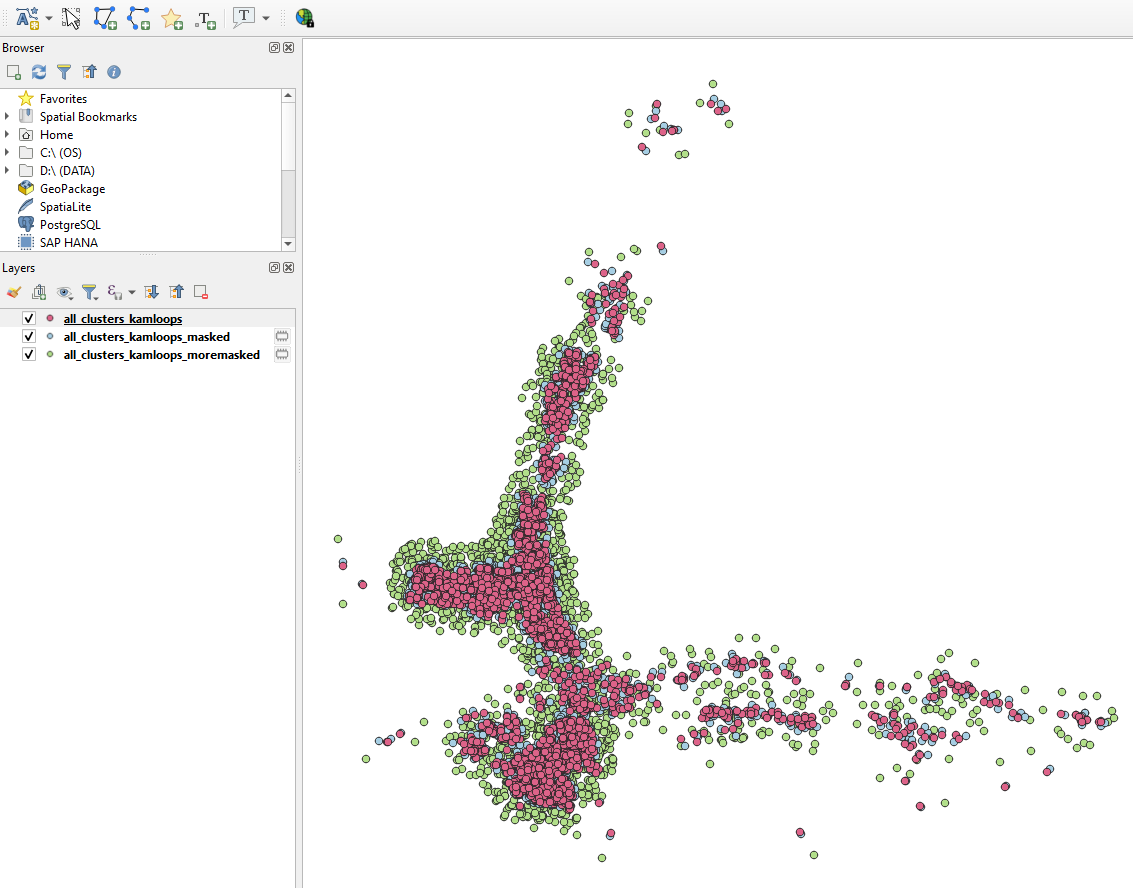
The first step in the geoprivacy plugin performs geographical masking to create masked representations of the original geographic dataset. The resulting datasets are shared with trusted users at different levels, to give them an approximate location of the sensitive locations they want to hide. Two-level masking allows two anonymised datasets to be created. The second level consists of a dataset that is masked with twice the user-provided minimum and maximum distances.
After uploading their confidential point-based geospatial dataset in QGIS, users define the following two parameters to transform point data:
(a) Minimum and (b) maximum masking distance. These two parameters are used to transform each point data to a specific distance at a random angle.
Then also specify if they want to perform an additional level of masking.
The three levels of masked datasets correlate with the following types of users:
- Trusted users who can have access to the original geographic dataset.
- Semi-trusted users who are trusted to some extent who need to see only approximate locations in the map.
- Untrusted users who are not trusted and should only see a heavily mask map.
To accommodate these three sets of users we generate two sets of masked datasets of the original dataset, to
cater for users with different security access. In doing so, the first level contains the original dataset, the second level
is masked using the parameters provided by the user, while for the third level of masking, the same parameters are used,
but increased by a certain constant. Using these masks not only provides stronger privacy protection but also produce
results that are more like the original data than previous generations of geographic masks.
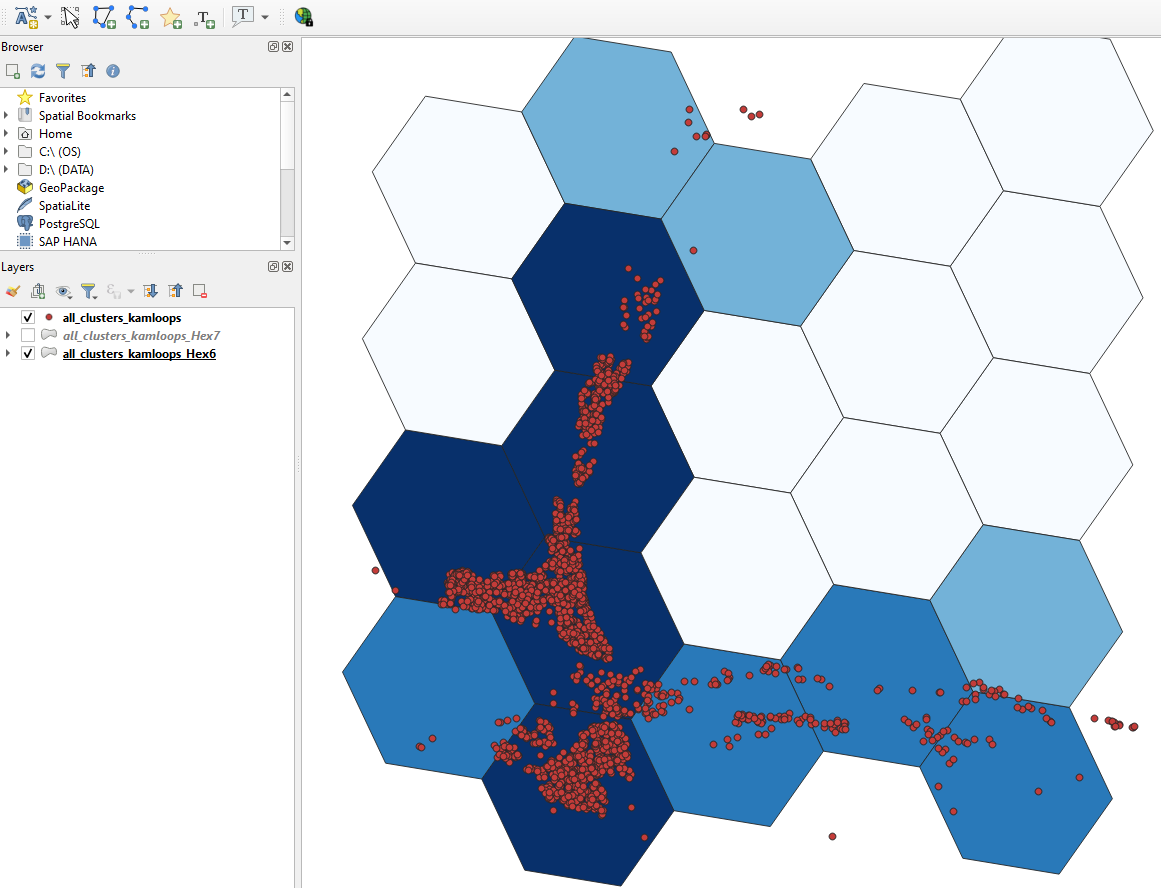
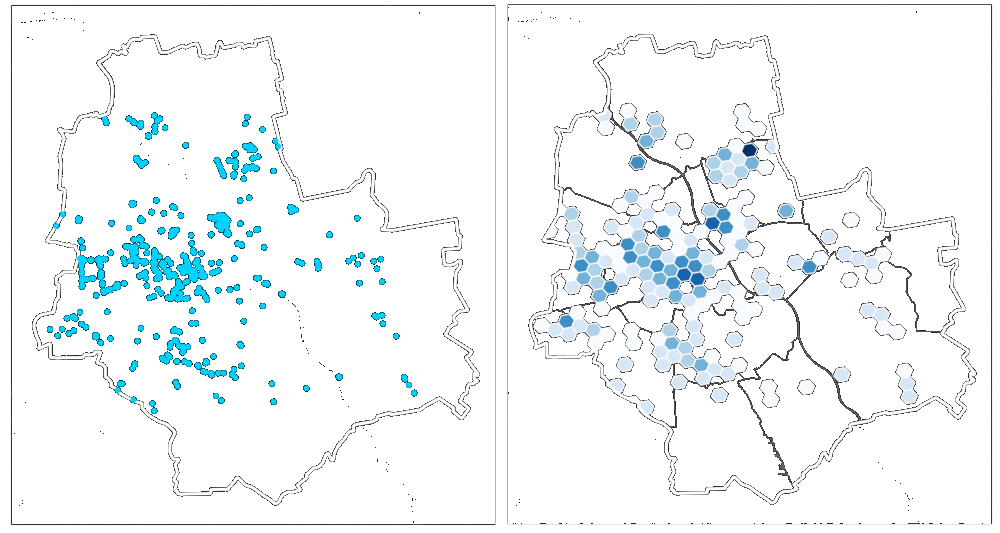
Hexagonal binning
Hexagonal binning (hexbinning) is the other option for anonymising geospatial datasets in the MapSafe plugin. This feature permits visualising the density of points and can be used instead of donut masking. Geographic points are aggregated into hexagonal cells using Uber's h3-py library Hexagons with more points are represented by darker cells, while those with fewer points are represented by lighter cells. Users can choose the spatial resolution (i.e., the Uber H3 spatial indexing level) along with the buffer radius for encoding. The buffer radius (in KM) allows specification of how far the coverage of the binning should span.
(Image acquired from https://www.kontur.io/blog/why-we-use-h3/)
Hexagonal Binning using the MapSafe Plugin
A suitable resolution must be chosen to balance privacy and utility depending on the area depicted in the dataset.
Large hexagons (lower resolution) would show many distant locations in the same cell, whereas small
hexagons (higher resolution) might show results that are too sparse to cover the entire area (refer to this paper).
Therefore, a resolution needs to be chosen that covers the entire area (i.e., dense representations) and
contains a small cell size (i.e., preserving location details) to better balance the trade-off between
spatial coverage and location details than other H3 indexing levels (paper).
Ema chooses a resolution of 7 (the level of a small city) for the all_clusters_kamloops dataset
and the results are shown in Figure below. The hexagonal binning process of generating hexabins and displaying them is instantaneous.
After pressing the Binning button, two binned layers are generated. These two layers cater for different user trust levels, as in the masking scheme. These layers also contain the counts.
The first generated layer is for the binning resolution
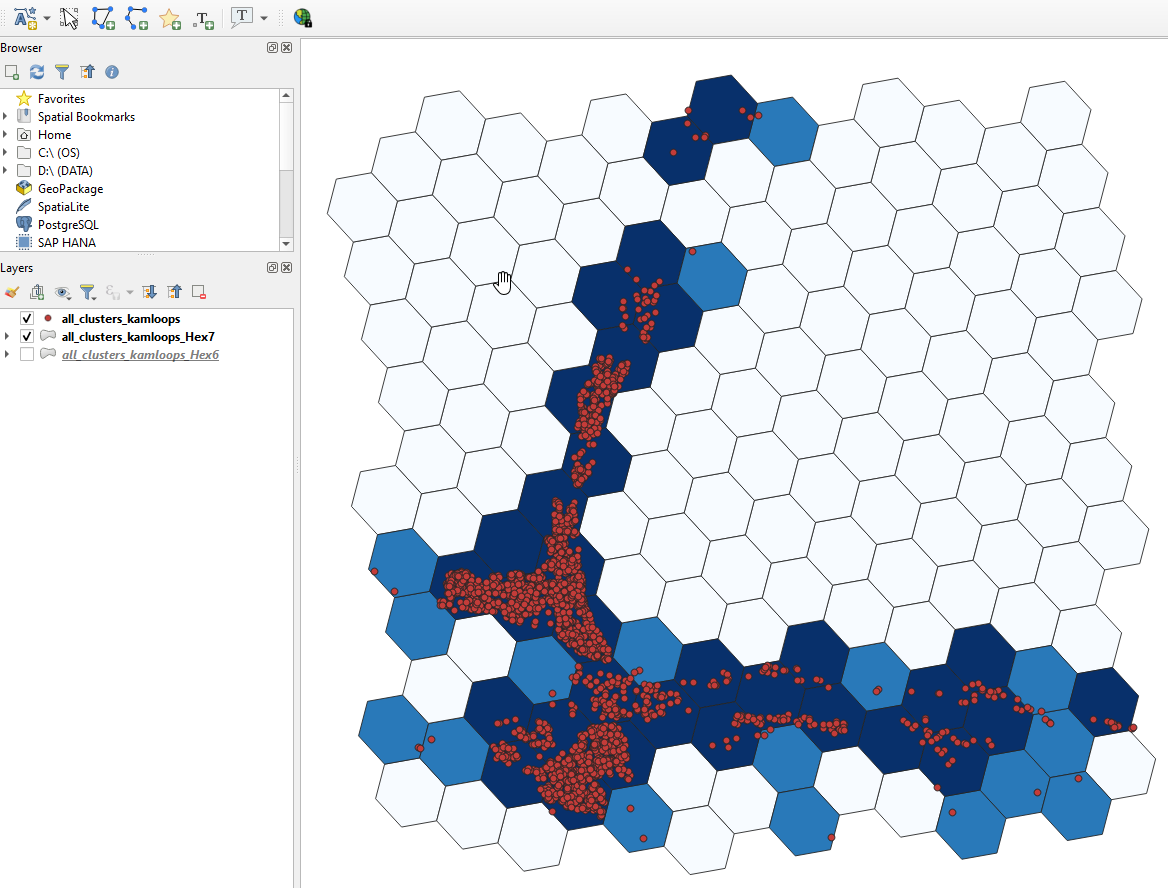
The other generated layer contains one extra binning resolution